[Python] 직장인을 위한 데이터 분석 실무 with 파이썬
Anaconda 설치 -> 주피터 노트북(코드 작성 시 결과 중간에 확인하여 분석 할 수 있는 툴) 실행
jupyter notebook다음과 같이 웹 브라우저에 서버 띄움
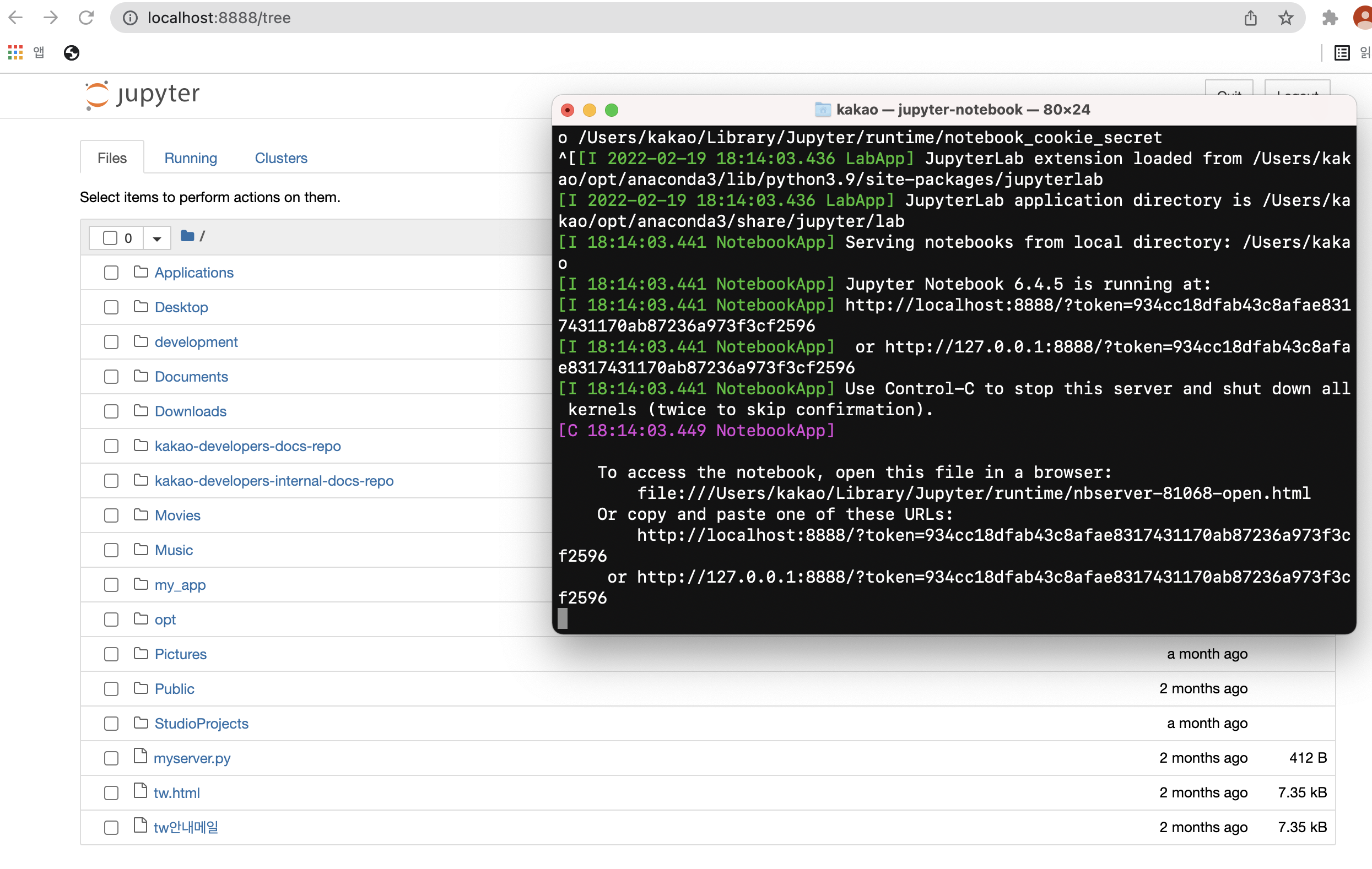
주피터 노트북에서 New>Python3을 눌러 파일 새로 추가

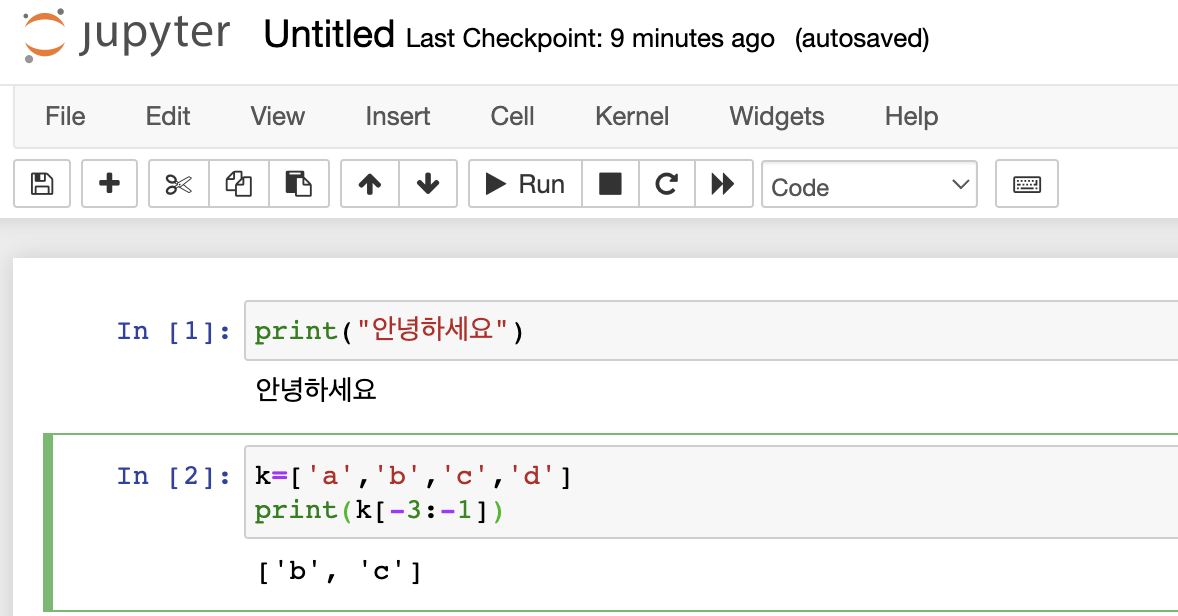
출력해보는 것 까지 완료. 이제 데이터를 가져와보자. 데이터가 저장된 위치 경로를 입력하고 사용할 열 입력. J열 데이터 중 5개만 가져오네? 상대 경로 입력 시 './files/sample.xlsx'
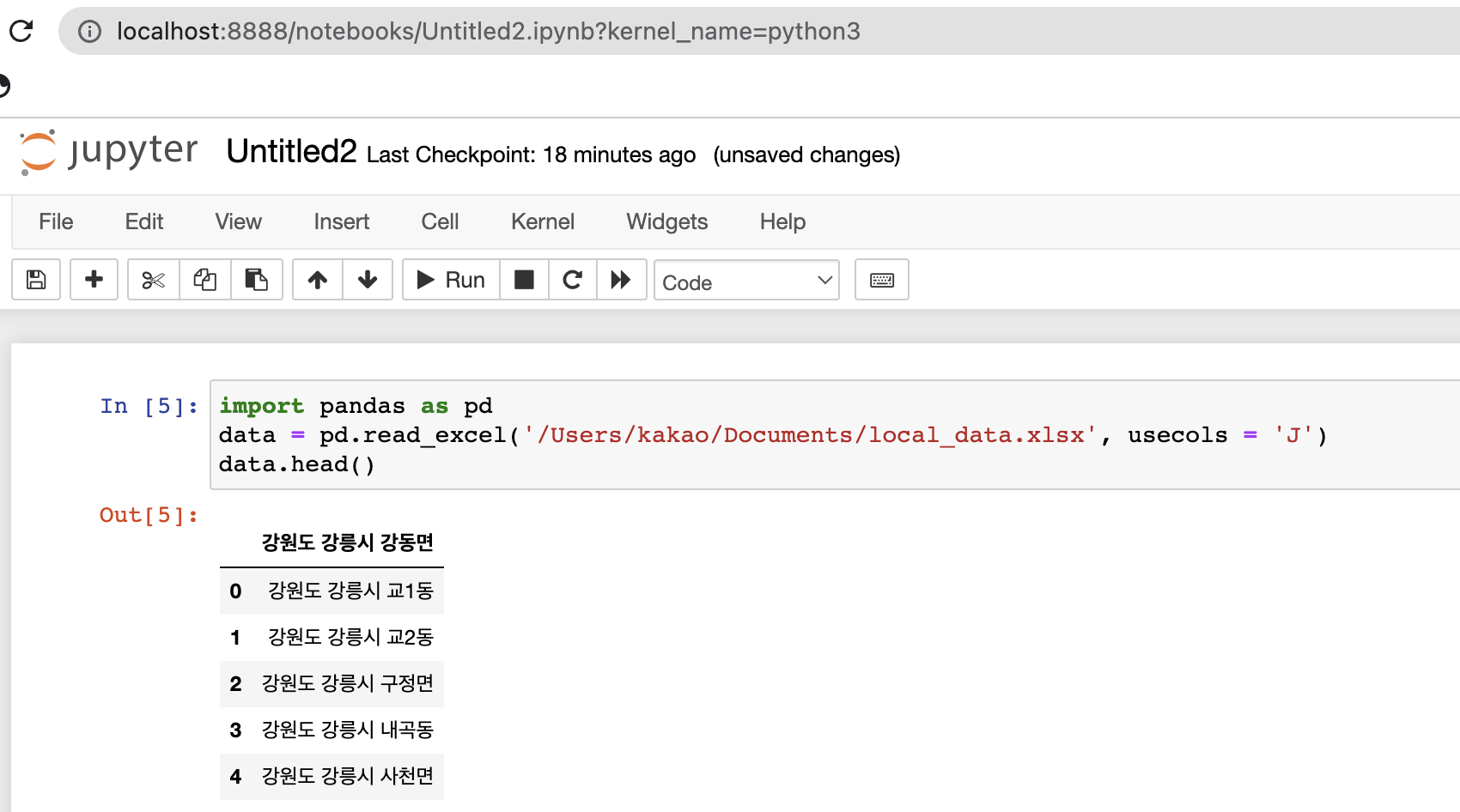
아하, head()값을 지정하지 않아서구나. head()는 처음부터 입력한 숫자의 로우까지 보여주는 함수. 지정하지 않았을 때 기본값이 5로 지정되나보네.

책에서 안내한대로 header를 입력하니 다음 에러 발생
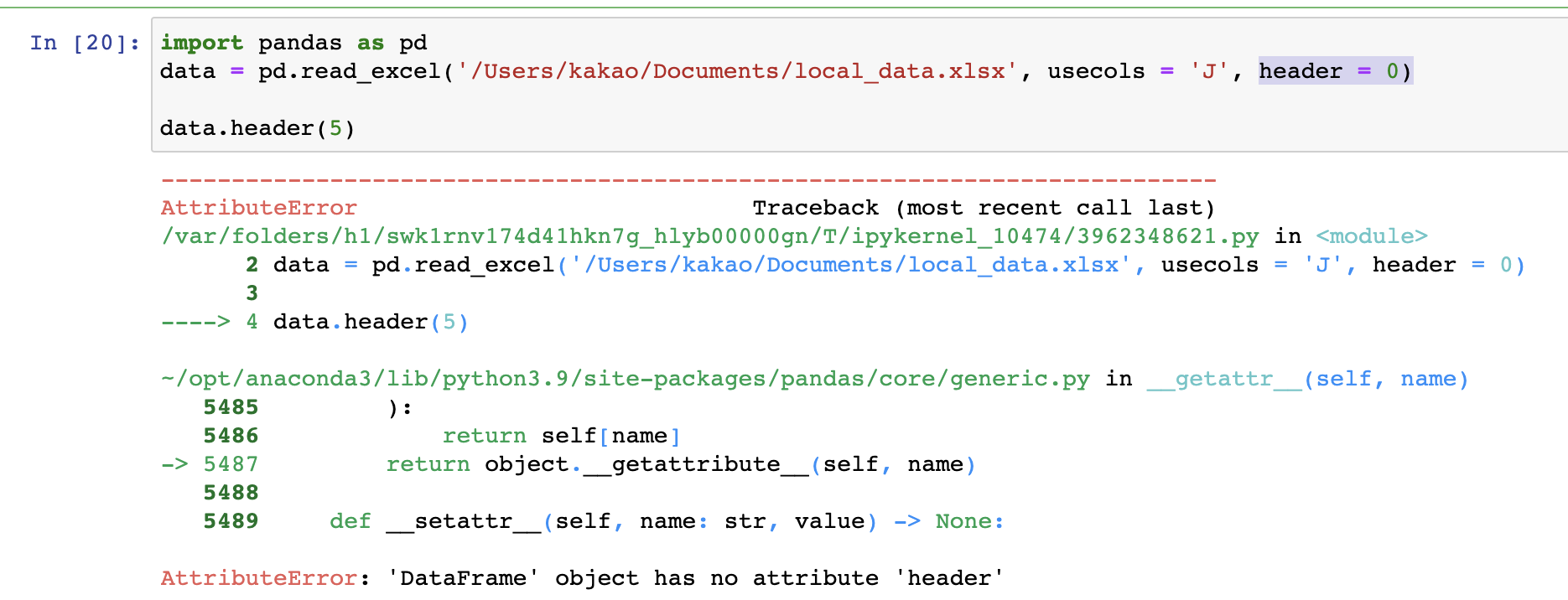
이유 찾음. J열만 지정해서... A:J로 컬럼 지정하니 잘 됨.
끝쪽에서부터 데이터를 확인하려면 tail() 사용. (-> header넣었을때도 에러 발생하지 않음)

데이터 정보를 확인하려면, *.info()

이렇게 data (변수명)만 따로 입력하고 Run해도 데이터가 잘 호출됨

다음과 같이 컬럼을 선택해서도 데이터 추출 가능.

데이터에 존재하지 않는 신규 칼럼 추가. 이 떄 원본 파일에는 변화 없음.

원본 데이터를 저장하려면, data.to_excel('file_path'). pandas에서 부여하는 인덱스번호가 자동삽입되므로, 이를 방지하려면 파라미터로 index=FALSE 지정

조건을 필터링하려면,
(1) condition이라는 변수를 선언에서 조건을 세우고, (이 때 condition을 호출하면 boolean 값으로 해당 조건에 맞는지 여부를 반환)
(2) 해당 data를 호출할때 condition 함께 전달: data[condition] -> condition에 맞는 데이터값만 출력.
